Key Collector — одна из самых популярных программ для сбора семантического ядра (о том, что это такое, мы писали в статье «Роль ключевых запросов в продвижении сайта»). С ней вы найдёте все ключевые запросы для своего сайта за полчаса. А дальше можно начинать продвижение: заказывать контент у копирайтеров или настраивать контекстную рекламу.
Key Collector предназначен для профессионалов, поэтому его интерфейс довольно сложный и недружелюбный. Слишком много кнопок и настроек. Но не переживайте, сейчас мы поможем вам во всём разобраться.
Шаг 1. Установка
Key Collector — платный сервис, стоит 1700 рублей. Никакой абонентской платы нет — вы покупаете программу один раз и навсегда.
Сперва программу нужно установить. Она работает только на OS Windows, версии для Mac OS нет. Что для этого нужно?
- 1. Скачайте Key Collector → key-collector.ru/buy.php . Не закрывайте страницу, она вам ещё нужна.
- 2. Запустите загруженный файл и следуйте инструкциям мастера установки.
- 3. Когда установка завершится, запустите саму программу и скопируйте код — HID.

- 4. Заполните форму заявки на сайте и вставьте в неё свой HID.

Важно указать только имя, еmail, HID и способ оплаты
- 5. Нажмите «Отправить заявку». Сотрудники Key Collector отправят вам письмо с подробными инструкциями о том, что делать дальше.
Теперь осталось только оплатить сервис — и вам пришлют ключ активации. Скачайте его и укажите программе путь к файлу ключа.

Всё, Key Collector активирован и готов к работе.
Шаг 2. Настройка
*В Key Collector много функций, но сейчас мы будем говорить лишь об основных.
Программа уже готова к работе — вы сможете собрать семантическое ядро и с базовыми настройками. Единственное, что нужно сделать до начала работы — указать свою учётную запись «Яндекса». Она нужна для работы.
Важно: не указывайте свой основной аккаунт. Если что-то пойдёт не так — его могут заблокировать.
Для этого:
- 1. Сначала создайте отдельную учетную запись специально для Key Collector. Это можно сделать здесь → yandex.ru/registration .
- 2. Теперь запускайте программу. Нажмите «Файл» → «Настройки».

- 3. Откройте раздел «Парсинг» → «Yandex.Direct». Кликните в пустое поле под «Логин Яндекс».

- 4. Сюда нужно написать свой логин. Если вы его не помните — это та часть почтового адреса, которая идет до @. В поле «Пароль Яндекс» впишите пароль.

- 5. Теперь нужно проверить аккаунт и активировать его. Нажмите на зеленую кнопку «Запустить» в этом же окне.

Проверка займёт около 10-20 секунд
- 6. Когда проверка закончится, можете начинать работу.
Закрывайте настройки — начинаем собирать ядро.
Шаг 3. Сбор слов
Мы будем собирать семантическое ядро на примере — «прокат автомобилей в Самаре». Для начала подумаем, по каким запросам нас могут искать клиенты:
- прокат авто,
- прокат автомобилей,
- аренда авто,
- машина напрокат,
- прокат авто Самара.
Если сможете придумать больше запросов — отлично. Например, можно указать марки автомобилей, которые у вас есть:
- прокат бмв,
- прокат bmw.
Важно подобрать фразы, которые характеризуют ваш бизнес. Если вы привозите пиццу на дом, ваш список будет выглядеть так:
- доставка пиццы,
- заказать пиццу,
- пицца Самара,
- пицца на заказ.
С теорией разобрались — давайте перейдём к практике.
Создайте новый проект.

Нажмите «Новый проект» и укажите, в какой папке сохранить файл
Для начала укажите регион, в котором вы работаете. Нажмите на кнопку внизу окна.

Задаём регион для сервиса «Яндекс.Вордстат»
Найдите в списке свой регион, отметьте его галочкой и нажмите «Сохранить изменения».

То же самое сделайте для остальных сервисов.

Выберите свой регион в остальных сервисах, которые использует Key Collector
Теперь подбирайте слова. Мы будем использовать сервис «Яндекс.Вордстат». Откройте инструмент «Пакетный сбор из левой колонки».

Сюда нужно добавить все запросы, которые вы придумали. Каждый запрос — с новой строки. Нажмите «Начать сбор», чтобы запустить поиск.

Чем больше фраз вы укажете — тем больше времени уйдёт на сбор. В нашем случае это заняло около 3 минут. Вот что получилось:


Колонка «Дата добавления» не нужна — только место на экране занимает. Скройте её, чтобы работать было удобнее. Кликните по ней правой кнопкой мыши и нажмите «Скрыть колонку».
В Key Collector много инструментов для сбора фраз, но хватит и одного «Вордстата». Остальные попробуете, когда разберётесь в программе. Продолжайте работу с ядром.
Шаг 4. Удаление дублей
Вы собрали все запросы, которые могут входить в семантическое ядро. Но среди них есть много «мусорных», лишних. Их стоит убрать.
Начнём с неявных дублей. Неявные дубли — это запросы, которые немного отличаются друг от друга, но поисковые системы считают их одинаковыми. Вам не нужно иметь несколько одинаковых запросов в ядре, поэтому найдите и удалите их.
Откройте вкладку «Данные» и выберите инструмент «Анализ неявных дублей».

Программа просканирует ваш список на наличие дублей. Если ничего не найдёт, предложит другой способ отбора — без учета словоформ. Вы можете включить этот режим и вручную поставить галочку возле параметра «Не учитывать словоформы при поиске».
Не забудьте нажать на кнопку «Выполнить поиск дублей повторно».

Key Collector нашел два дубля: «аренда авто на часы» и «аренда авто на час». Один из них нужно выделить. Вы можете сделать это вручную. Но если дублей много, выделять их вручную долго. Лучше используйте инструмент «Умная отметка» — он автоматически выделит по одной фразе в каждой группе дублей.

Закройте окно, фразы останутся отмеченными. Вы можете просто удалить их. Но обычно сеошники так не делают. В программе есть специальная папка «Корзина», куда складывают ненужные фразы. Мало ли что, вдруг потом пригодятся.
Чтобы перенести отмеченные фразы, вернитесь в раздел «Сбор данных» и нажмите «Перенос фраз в другую группу».

Выберите группу, в которую хотите перенести фразы. В нашем случае это «Корзина».

Поставьте галочки напротив пунктов «Перенос» и «Отмеченных». Нажмите «Ок».
Готово, дубль в корзине. Переходим к следующему пункту очистки ядра от мусора.
Шаг 5. Удаление стоп-слов
Скорее всего, большая часть запросов в списке вам не подходит. Они для другого города или вы не оказываете такие услуги. Поэтому все лишние фразы нужно убрать.
Мы будем убирать лишние фразы с помощью списка стоп-слов. Если добавить в этот список слово — программа проверит семантическое ядро и выделит все фразы, в которых оно встречается. Дальше их можно удалить или перенести в корзину.
Давайте подумаем, какие слова можно исключать для любого типа бизнеса:
- Фото, фотка, фотография, картинка, иллюстрация, видео — иногда людям нужна картинка того, чем вы занимаетесь, чтобы отправить её друзьям или добавить в презентацию. Это точно не ваши клиенты — смело их отфильтровываем.
- Бренды конкурентов — если кто-то ищет вашего конкурента, вряд ли он зайдёт на ваш сайт. Убираем.
- Дёшево, недорого — можно оставить, если низкие цены — ваше реальное преимущество. Если нет — убираем.
- Бесплатно, скачать, торрент, torrent — как и в случае с картинками, это вообще не наши клиенты.
- Реферат, википедия, вики, wiki — аналогично, удаляем.
В нашем случае добавим в список марки машин, которых у нас нет, и слово «купить» — мы ничего не продаём. Давайте занесём все это в Key Collector.
Кликните по кнопке «Стоп-слова».

Нажмите значок «Добавить списком».

Кликните по зелёному плюсику
Напишите свой список стоп-слов. Стоп-слово — это необязательно одно слово. Можно указывать целые фразы, которые вам не нужны.
Если указываете бренды — пишите названия и на русском, и на английском. Слова лучше писать без окончаний — стоп-слово «москв» удалит фразы с «Москва», «в Москве», «для Москвы».


Отмечаем все фразы, в которых есть стоп-слова
Закрывайте окно стоп-слов, фразы останутся выделенными. Сразу перенесите их в корзину.
Теперь начинается самая сложная и долгая часть составления семантического ядра. Вам нужно просмотреть все собранные фразы и выбрать из них «мусорные». Заодно нужно дополнять список стоп-слов, чтобы облегчить процесс расширения ядра в будущем.
Просмотрите список. Когда вы находите ненужную фразу, выделяйте её и нажимайте на значок «Отправить фразу в окно стоп-слов».

Выберите, какие слова из фразы нужно добавить в список, и нажмите «Добавить в стоп-слова».

Просмотрите ядро до самого конца, дополните список стоп-слов, а лишние фразы отправьте в корзину.
Есть ещё один инструмент, который немного облегчит вам задачу. Перейдите во вкладку «Данные» и откройте «Анализ групп».

В этом окне фразы группируются по заданным критериям. Вы можете выделить сразу несколько фраз одним нажатием. По умолчанию стоит группировка по отдельным словам. Все фразы с одинаковыми словами попадают в одну группу — это нам и нужно.
Пройдитесь по этому списку и отметьте ненужные слова. Так вы выберете все фразы, в которых они встречаются. Не забывайте добавлять их в список стоп-слов.

Чёрный квадратик означает, что в этой группе некоторые фразы выделены, а некоторые — нет
Так вы оставите в семантическом ядре только нужные фразы и составите полный список стоп-слов. Переходим к следующему пункту.
Шаг 6. Определение точной частотности
При сборе фраз с помощью «Вордстата» вы получаете базовую частотность. Это неточный показатель, ориентироваться на него не стоит. Давайте подберём точную частотность для нашего семантического ядра.
Для этого мы будем использовать инструмент «Сбор статистики Yandex.Direct».

Укажите, что хотите заполнять колонки вида «слово» (в кавычках). Кавычки как раз и дают нам точную частотность. Запускаем.

Как видите, точная частота сильно отличается от базовой. По ней вы и будете определять популярность запросов.

Наше семантическое ядро готово.
Шаг 7. Экспорт
Экспортируйте ядро из Key Collector. Нажмите «Файл» → «Экспорт» и укажите папку, в которую хотите сохранить таблицу с фразами. Формат (CSV или XLSX) можно задать в настройках.

Повторим ещё раз
Итак, мы собрали семантическое ядро для компании, которая занимается прокатом автомобилей в Самаре. Давайте перечислим последовательность действий:
- 1. Создать отдельный аккаунт в «Яндексе» и подключить его к Key Collector.
- 2. Придумать список фраз, которые характеризуют ваш бизнес.
- 3. Собрать фразы из «Яндекс.Вордстата».
- 4. Удалить неявные дубли.
- 5. Создать список стоп-слов, удалить «мусорные фразы».
- 6. Загрузить точную частотность из «Яндекс.Директа».
- 7. Экспортировать готовое семантическое ядро и список стоп-слов.
Теперь вы умеете работать с Key Collector и сможете составить семантическое ядро для своего сайта без помощи сеошника.
И использует для этого Key Collector предлагаю воспользоваться базой стоп-слов для очистки мусора. Для всех остальных рекомендую обратиться ко мне и , и тогда вам не придётся мучиться, разгребать и группировать тысячи фраз, всё это сделаю за вас я 🙂
Базы стоп-слов для Key Collector
Эту базу я собрал из обрывков и осколков стоп-слов для Кей Коллектора, которые можно найти на просторах Интернета. На мой взгляд это наиболее полный список всех минус-слов, который есть на сегодняшний день, поэтому настоятельно рекомендую воспользоваться им для чистки семантического ядра.
- Список стоп-слов для KeyCollector по всем городам России, Украины и Беларусии.
- Списки минус-слов для фильтрации: XXX-тематики, “Сделай сам”, ремонт, юмор и т.д.
- Список мужских и женских имён.
- Стоп-слова для Кей Коллектора разбитые по тематикам (!) – тематик правда не много, но тем не менее.
Этих баз действительно хватит для очистки 95% мусора, который встречается при сборе семантики, но руками всё же придётся поработать всё равно. Тем не менее благодаря использованию этих стоп-слов я начал экономить часы времени на очистку ядер, раньше это была откровенная попоболь!
Key Collector — один из основных инструментов SEO-оптимизатора. Эта программа, созданная для подбора семантического ядра, входит в категорию маст-хэв инструментов для продвижения. Она так же важна, как скальпель для хирурга или штурвал — для пилота. Ведь без ключевых слов немыслима.
В этой статье рассмотрим, что такое Кей Коллектор и как с ним работать.
Для чего нужен Key Collector
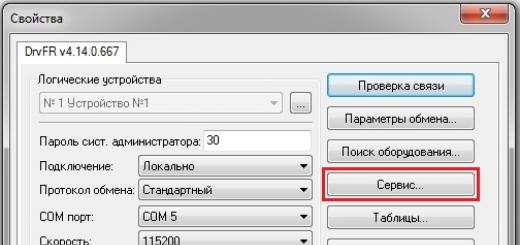
Затем зайдите в настройки (кнопка шестерёнки в панели в верхнем левом углу окна программы) и найдите вкладку «Yandex.Direct «.
Нажмите на кнопку «Добавить списком » и введите созданные аккаунты в формате логин:пароль .
Внимание! добавлять @yandex.ru после логина не нужно!
После всех операций получится примерно следующее:
Но и это ещё не всё. Теперь нужно создать аккаунт Google AdWords, который будет привязан к данному аккаунту Google. Без аккаунта в AdWords получать данные по ключевым словам будет невозможно, так как они берутся именно оттуда. При создании аккаунта выберите язык, часовой пояс и валюту. Учтите, что эти данные нельзя будет изменить .
После создания аккаунта AdWords вновь откройте настройки Key Collector и вкладку «Google.AdWords «. Здесь в настройках рекомендуется использовать только один аккаунт Google.
Антикапча
Этот пункт не является обязательным, но я всё же рекомендую использовать антикапчу. Конечно, если вам нравится каждый раз вводить капчу вручную, дело ваше. Но если вам не хочется тратить на это своё время, найдите в настройках вкладку «Антикапча», включите радиокнопку «Antigate» (или любой другой из предложенных вариантов) и в появившемся поле введите свой ключ антикачи. Если у вас ещё нет ключа, создайте его.
Распознавание капчи — это платная услуга, но 10 долларов хватает минимум на месяц. К тому же если вы не занимаетесь парсингом поисковиков ежедневно, этой суммы хватит и на год.
Прокси
По умолчанию программа использует для парсинга ваш основной IP-адрес. Если пользоваться Кей Коллектором часто вам не потребуется, на настройки прокси можно забить. Но если вы часто работаете с программой, поисковики могут часто подсовывать вам капчу и даже временно банить ваш IP. К тому же будут страдать все пользователи, которые выходят в Сеть под общим IP. Такая проблема встречается, например, в офисах.
Также трудности при парсинге Яндекса с основного IP могут испытывать пользователи из Украины.
Найти бесплатные прокси, которые всё ещё не в бане поисковиков, бывает довольно сложно. Если у вас есть список таких адресов, введите их в настройках во вкладке «Сеть «. Затем нажмите на кнопку «Добавить строку «.
Другой вариант — создайте файл с адресами в формате IP:порт , скопируйте их в буфер обмена и добавьте в коллектор с помощью кнопки «Добавить из буфера «.
Но я рекомендую подключить платный VPN от hidemy.name . В этом случае на компьютер устанавливается приложение, которое включает/выключает VPN по требованию. В этом приложении также можно изменять сам прокси и его страну. Дополнительно не придётся ничего настраивать. Просто включаете VPN и комфортно работаете с Коллектором.
Я перечислил основные настройки, которые нужны для старта работы. Советую самостоятельно пройтись по всем вкладкам и изучить настройки программы. Может быть, вы найдёте пункты в настройках, которые окажутся нужны именно вам.
Подбор ключевых слов с Key Collector
Наконец-то мы дошли до собственно подбора семантического ядра. В главном окне программы нажмите на большую кнопку «Новый проект «. Советую назвать файл проекта именем сайта, например, site.ru, и сохранить в специально созданную папку для проектов Key Collector, чтобы потом не тратить время на поиски.
В Коллекторе удобно сортировать ключевые слова по группам. Мне удобно, когда иерархия групп в проекте соответствует будущей , поэтому первая группа (группа по умолчанию) у меня соответствует главной странице сайта.
Для примера поработаем с тематикой «создание сайтов Москва». Начнём с Яндекса.
Сначала нужно задать регион:
Теперь нужно открыть «Пакетный сбор слов из левой колонки Yandex.Wordstat » и в возникшем окне ввести штук 5 наиболее очевидных в данной тематике ключевых фраз (на их основе будет производиться парсинг).
Теперь нужно нажать на кнопку «Начать сбор «.
Всё, можно пойти заварить кофе или переключиться на другие задачи. Кей Коллектору потребуется некоторое время, чтобы спарсить ключевые фразы.
В результате отобразится примерно следующее:
Стоп-слова
Теперь нужно отфильтровать неподходящие в данный момент слова и фразы. Например, сочетание слов «создание сайтов москва бесплатно » не подойдёт, так как бесплатных услуг мы не предоставляем. Искать такие фразы вручную в семантическом ядре на сотни и тысячи запросов занятие крайне увлекательное, но лучше всё же воспользоваться специальным инструментом.
Затем нужно нажать на плюсик:
Вероятно, вы заметили, что в программе есть большое количество различных опций при работе с ключевыми словами. Я объясняю основные, самые простые операции в Key Collector.
Работа с частотностью запросов
После фильтрации по минус-словам можно запустить парсинг по частотности.
Сейчас мы видим только колонку с общей частотностью. Чтобы получить точную частотность по каждому ключевому слову, нужно в Вордстате ввести его в операторе кавычки — «ключевое слово».
В Коллекторе это делается следующим образом:
При необходимости можно собрать частотность с оператором «!слово».
Затем нужно отсортировать список по частотности » » и удалить слова с частотностью менее 10 (иногда 20-30).
Второй способ собрать частотность (более медленный):
Если вы точно знаете, что частотность ниже определённого значения вас не интересует, можно задать порог в настройках программы. В этом случае фразы с частотностью ниже порога вообще не будут попадать в список. Но так можно упустить перспективные фразы, поэтому я эту настройку не использую и вам не советую. Впрочем, действуйте по своему усмотрению.
В итоге получается более-менее пригодное для последующей работы семантическое ядро:
Обратите внимание, что это семантическое ядро — лишь пример, созданный только для демонстрации работы программы. Оно не годится под реальный проект, так как слабо проработано.
Правая колонка Yandex.Wordstat
Иногда есть смысл парсить правую колонку Вордстата (запросы, похожие на «ваш запрос»). Для этого нужно кликнуть на соответствующую кнопку:
Google и Key Collector
Запросы из статистики Google парсятся по аналогии с Яндексом. Если вы создали аккаунт Google и аккаунт AdWords (как мы помним, одного лишь аккаунта Google недостаточно), нажмите на соответствующую кнопку:
В открывшемся окне введите интересующие запросы и запустите подбор. Всё по аналогии с парсингом Вордстата. Если необходимо, в этом же окне укажите дополнительные настройки конкретно для Google (при клике на значок вопроса появится справка).
В итоге вы получите следующие данные по AdWords:
И сможете продолжить работу с семантикой.
Выводы
Мы разобрали базовые настройки Key Collector (то, без чего невозможно начать работать). Также мы рассмотрели самые простые (и основные) примеры использования программы. И подобрали простенькое семантическое ядро, используя статистику Яндекс.Вордстат и Google AdWords.
Как вы понимаете, в статье показано примерно 20% от всех возможностей программы. Чтобы освоить Key Collector, нужно потратить несколько часов и изучить официальный мануал. Но оно того стоит.
Если после этой статьи вы решили, что проще заказать семантическое ядро у специалистов, чем разбираться самому, напишите мне через страницу , и мы обсудим детали.
И бонусное видео: чувак по имени Derek Brown виртуозно играет на саксофоне. Я даже побывал на его концерте во время джаз-фестиваля, это реально круто.
Начал писать эту статью довольно давно, но перед самой публикацией оказалось, что меня опередили соратники по профессии и выложили практически идентичный материал.
Поначалу я решил, что публиковать свою статью не буду, так как тему и без того прекрасно осветили более опытные коллеги. Михаил Шакин рассказал о 9-ти способах чистки запросов в KC , а Игорь Бакалов отснял видео об анализе неявных дублей . Однако, спустя какое-то время, взвесив все за и против, пришел к выводу, что возможно моя статья имеет право на жизнь и кому-то может пригодиться – не судите строго.
Если вам необходимо отфильтровать большую базу ключевых слов, состоящую из 200к или 2 миллионов запросов, то эта статья может вам помочь. Если же вы работаете с малыми семантическими ядрами, то скорее всего, статья не будет для вас особо полезной.
Рассматривать фильтрацию большого семантического ядра будем на примере выборки, состоящей из 1 миллиона запросов по юридической теме.
Что нам понадобится?
- Key Collector (Далее KC)
- Минимум 8гб оперативной памяти (иначе нас ждут адские тормоза, испорченное настроение, ненависть, злоба и реки крови в глазных капиллярах)
- Общие Стоп-слова
- Базовое знание языка регулярных выражений
Если вы совсем новичок в этом деле и с KC не в лучших друзьях, то настоятельно рекомендую ознакомиться с внутренним функционалом , описанным на официальных страницах сайта. Многие вопросы отпадут сами собой, также вы немножечко разберетесь в регулярках.
Итак, у нас есть большая база ключей, которые необходимо отфильтровать. Получить базу можно посредством самостоятельного парсинга, а также из различных источников, но сегодня не об этом.
Всё, что будет описано далее актуально на примере одной конкретной ниши и не является аксиомой! В других нишах часть действий и этапов могут существенно отличаться ! Я не претендую на звание Гуру семантика, а лишь делюсь своими мыслями, наработками и соображениями на данный счет.
Шаг 1. Удаляем латинские символы
Удаляем все фразы, в которых встречаются латинские символы. Как правило, у таких фраз ничтожная частотка (если она вообще есть) и они либо ошибочны, либо не относятся к делу.
Все манипуляции с выборками по фразам проделываются через вот эту заветную кнопку

Если вы взяли миллионное ядро и дошли до этого шага – то здесь глазные капилляры могут начать лопаться, т.к. на слабых компьютерах/ноутбуках любые манипуляции с крупным СЯ могут, должны и будут безбожно тормозить.
Выделяем/отмечаем все фразы и удаляем.
Шаг 2. Удаляем спец. Символы
Операция аналогична удалению латинских символов (можно проводить обе за раз), однако я рекомендую делать все поэтапно и просматривать результаты глазами, а не «рубить с плеча», т.к. порой даже в нише, о которой вы знаете, казалось бы, все, встречаются вкусные запросы, которые могут попасть под фильтр и о которых вы могли попросту не знать.

Небольшой совет, если у вас в выборке встречается множество хороших фраз, но с запятой или другим символом, просто добавьте данный символ в исключения и всё.
Еще один вариант (самурайский путь)
- Выгрузите все нужные фразы со спецсимволами
- Удалите их в KC
- В любом текстовом редакторе замените данный символ на пробел
- Загрузите обратно.
Теперь фразоньки чисты, репутация их отбелена и выборка по спец. символам их не затронет.
Шаг 3. Удаляем повторы слов
И снова воспользуемся встроенным в KC функционалом, применив правило
Тут и дополнить нечем – все просто. Убиваем мусор без доли сомнения.
Если перед вами стоит задача произвести жесткую фильтрацию и удалить максимум мусора, при этом пожертвовав какой-то долей хороших запросов, то можете все 3 первых шага объединить в один .
Выглядеть это будет так:

ВАЖНО: Не забудьте переключить «И» на «ИЛИ»!
Шаг 4. Удаляем фразы, состоящие из 1 и 7+ слов
Кто-то может возразить и рассказать о крутости однословников, не вопрос – оставляйте, но в большинстве случаев ручная фильтрация однословников занимает очень много времени, как правило соотношение хороший/плохой однословник – 1/20, не в нашу пользу. Да и вбить их в ТОП посредством тех методов, для которых я собираю такие ядра из разряда фантастики. Поэтому, поскрипывая сердечком отправляем словечки к праотцам.

Предугадываю вопрос многих, «зачем длинные фразы удалять»? Отвечаю, фразы, состоящие из 7 и более слов по большей части, имеют спамную конструкцию, не имеют частотку и в общей массе образуют очень много дублей, дублей именно тематических. Приведу пример, чтоб было понятней.

К тому же частотка у подобных вопросов настолько мала, что зачастую место на сервере обходится дороже, чем выхлоп от таких запросов. К тому же, если вы просмотрите ТОП-ы по длинным фразам, то прямых вхождений ни в тексте ни в тегах не найдете, так что использование таких длинных фраз в нашем СЯ – не имеет смысла.
Шаг 5. Очистка неявных дублей
Предварительно настраиваем очистку, дополняя своими фразами, указываю ссылку на свой список, если есть, чем дополнить – пишите, будем стремиться к совершенству вместе.

Если этого не сделать, и использовать список, любезно предоставленный и вбитый в программу создателями KC по умолчанию, то вот такие результаты у нас останутся в списке, а это, по сути, очень даже дубли.

Можем выполнить умную группировку, но для того, чтобы она отработала корректно – необходимо снять частотку. А это, в нашем случае не вариант. Т.к. Снимать частотку с 1млн. кеев, да пусть хоть со 100к – понадобится пачка приватных проксей, антикапча и очень много времени. Т.к. даже 20 проксей не хватит – уже через час начнет вылезать капча, как не крути. И займет это дело очень много времени, кстати, бюджет антикапчи тоже пожрет изрядно. Да и зачем вообще снимать частотку с мусорных фраз, которые можно отфильтровать без особых усилий?
Если же вы все-таки хотите отфильтровать фразы с умной группировкой, снимая частотности и поэтапно удаляя мусор, то расписывать процесс подробно не буду – смотрите видео, на которое я сослался в самом начале статьи.
Вот мои настройки по очистке и последовательность шагов

Шаг 6. Фильтруем по стоп-словам
На мой взгляд – это самый муторный пункт, выпейте чая, покурите сигаретку (это не призыв, лучше бросить курить и сожрать печеньку) и со свежими силами сядьте за фильтрацию семантического ядра по стоп-словам.
Не стоит изобретать велосипед и с нуля начинать составлять списки стоп-слов. Есть готовые решения. В частности, вот вам , в качестве основы более, чем пойдет.
Советую скопировать табличку в закорма собственного ПК, а то вдруг братья Шестаковы решат оставить «вашу прелесть» себе и доступ к файлику прикроют? Как говорится «Если у вас паранойя, это еще не значит, что за вами не следят…»
Лично я разгрупировал стоп-слова по отдельным файлам для тех или иных задач, пример на скриншоте.

Файл «Общий список» содержит все стоп-слова сразу. В Кей Коллекторе открываем интерфейс стоп-слов и подгружаем список из файла.

Я ставлю именно частичное вхождение и галочку в пункте «Искать совпадения только в начале слов». Данные настройки особенно актуальны при огромном объеме стоп-слов по той причине, что множество слов состоят из 3-4 символов. И если поставите другие настройки, то вполне можете отфильтровать массу полезных и нужных слов.
Если мы не поставим вышеуказанную галочку, то пошлое стоп-слово «трах» найдется в таких фразах как «консультация государственного страхования» , «как застраховать вклады» и т.д. и т.п. Вот ещё пример, по стоп слову «рб» (республика Беларусь) будет отмечено огромное кол-во фраз, по типу «возмещение ущерба консультация», «предъявление иска в арбитражном процессе» и т.д. и т.п.
Иными словами — нам нужно, чтобы программа выделяла только фразы, где стоп-слова встречаются в начале слов. Формулировка ухо режет, но из песни слов не выкинешь.
Отдельно замечу, что данная настройка приводит к существенному увеличению времени проверки стоп слов. При большом списке процесс может занять и 10 и 40 минут, а все из-за этой галочки, которая увеличивает время поиска стос-слов во фразах в десять, а то и более раз. Однако это наиболее адекватный вариант фильтрации при работе с большим семантическим ядром.
После того как мы прошлись по базовым списком рекомендую глазами просмотреть не попали ли под раздачу какие-то нужные фразы, а я уверен, так оно и будет, т.к. общие списки базовых стоп-слов, не универсальны и под каждую нишу приходится прорабатывать отдельно. Вот тут и начинаются «танцы с бубном.
Оставляем в рабочем окне только выделенные стоп слов, делается это вот так.

Затем нажимаем на «анализ групп», выбираем режим «по отдельным словам» и смотрим, что лишнего попало в наш список из-за неподходящих стоп-слов.

Удаляем неподходящие стоп-слова и повторяем цикл. Таким образом через некоторое время мы «заточим» универсальный общедоступный список под наши нужды. Но это еще не все.
Теперь нам нужно подобрать стоп-слова, которые встречаются конкретно в нашей базе. Когда речь идет об огромных базах ключевиков, там всегда есть какой-то «фирменный мусор», как я его называю. Причем это может быть совершенно неожиданный набор бреда и от него приходится избавляться в индивидуальном порядке.
Для того, чтобы решить эту задачку мы снова прибегнем к функционалу Анализа групп, но на этот раз пройдемся по всем фразам, оставшимся в базе, после предыдущих манипуляций. Отсортируем по количеству фраз и глазами, да-да-да, именно ручками и глазами, просмотрим все фразы, до 30-50 в группе. Я имею в виду вторую колонку «кол-во фраз в группе».
Слабонервных поспешу предупредить, на первый взгляд бесконечный ползунок прокрутки», не заставит вас потратить неделю на фильтрацию, прокрутите его на 10% и вы уже дойдете до групп, в которых содержится не более 30 запросов, а такие фильтровать стоит только тем, кто знает толк в извращениях.
Прямо из этого же окна мы можем добавлять весь мусор в стоп слова (значок щита слева от селектбокса).

Вместо того, чтобы добавлять все эти стоп слова (а их гораздо больше, просто я не хотел добавлять длиннющий по вертикали скриншот), мы изящно добавляем корень «фильтрац» и сразу отсекаем все вариации. В результате наши списки стоп-слов не будут разрастаться до огромных размеров и что самое главное, мы не будем тратить лишнее время на их поиск . А на больших объемах — это очень важно.
Шаг 7. Удаляем 1 и 2 символьные «слова»
Не могу подобрать точное определение к данному типу сочетания символов, поэтому обозвал «словами». Возможно, кто-то из прочитавших статью подскажет, какой термин подойдет лучше, и я заменю. Вот такой вот я косноязычный.
Многие спросят, «зачем вообще это делать»? Ответ прост, очень часто в таких массивах ключевых слов встречается мусор по типу:

Общий признак у таких фраз — 1 или 2 символа, не имеющие никакого смысла (на скриншоте пример с 1 символм). Вот это мы и будем фильтровать. Здесь есть свои подводные камни, но обо всем по порядку.
Как убрать все слова, состоящие из 2-х символов?
Для этого используем регулярку

Дополнительный совет: Всегда сохраняйте шаблоны регулярок! Они сохраняются не в рамках проекта, а в рамках KC в целом . Так что будут всегда под рукой.
(^|\s+)(..)(\s+|$) или же (^|\s){1,2}(\s|$)
(ст | фз | ук | на | рф | ли | по | ст | не | ип | до | от | за | по | из | об)
Вот мой вариант, кастомизируйте под свои нужды.
Вторая строка – это исключения, если их не вписать, то все фразы, где встречаются сочетания символов из второй строки формулы, попадут в список кандидатов на удаление.
Третья строка исключает фразы, в конце которых встречается «рф», т.к. зачастую это нормальные полезные фразы.
Отдельно хочу уточнить, что вариант (^|\s+)(..)(\s+|$) будет выделять все – в том числе и числовые значения . Тогда как регулярка (^|\s){1,2}(\s|$) – затронет лишь буквенные, за неё отдельное спасибо Игорю Бакалову.
Применяем нашу конструкцию и удаляем мусорные фразы.
Как убрать все слова, состоящие из 1 символа?
Здесь все несколько интересней и не так однозначно.
Сначала я попробовал применить и модернизировать предыдущий вариант, но в результате выкосить весь мусор не получилось, тем не менее – многим подойдет именно такая схема, попробуйте.

(^|\s+)(.)(\s+|$)
(с | в | и | я | к | у | о)
Традиционно – первая строка сама регулярка, вторая – исключения, третья – исключает те фразы, в которых перечисленные символы встречаются в начале фразы. Ну, оно то и логично, ведь перед ними не стоит пробела, следовательно, вторая строка не исключит их присутствие в выборке.
А вот второй вариант при помощи которого я и удаляю все фразы с односимвольным мусором, простой и беспощадной, который в моем случае помог избавиться от очень большого объема левых фраз.

(й | ц | е | н | г | ш | щ | з | х | ъ | ф | ы | а | п | р | л | д | ж | э | ч | м | т | ь | б | ю)
Я исключил из выборки все фразы, где встречается «Москв», потому что было очень много фраз по типу:

а мне оно нужно сами догадываетесь для чего.
Дорогие друзья, сегодня я хочу рассказать о том, как эффективно чистить поисковые запросы в программе Key Collector http://www.key-collector.ru/ .
Чтобы почистить семантическое ядро, я использую следующие способы:
- Чистка семантического ядра с помощью регулярных выражений.
- Удаление с помощью списка стоп-слов.
- Удаление с помощью групп слов.
- Чистка по фильтру.
Их использование позволит вам быстро и эффективно почистить список собранных ключевых слов и удалить все фразы, которые не подходят для вашего сайта.
Чтобы все наглядно показать, я решил записать видеоурок:
Обзор лучше смотреть в полноэкранном режиме в качестве 720 HD. Также не забывайте подписываться на мой канал на Youtube, чтобы не пропустить новые видео.
Я покажу несколько способов это сделать. Если вы знаете еще способы – черкните в комментариях. Все описанные методы я сам использую. Они экономят мне массу времени.
Итак, поехали.
Регулярные выражения значительно расширяют возможности по выборке запросов и экономят время.
Допустим, нам нужно выбрать все поисковые запросы, которые содержат цифры.
Для этого кликаем на указанной иконке в колонке "Фраза":

Выбираем опцию "удовлетворяет рег. выражению" и вставляем в поле такое регулярное выражение:

Остается нажать кнопку "Применить", и вы получите список всех запросов, которые содержат цифры.
Я люблю применять регулярные выражения для поиска поисковых запросов, которые представляют собой вопросы.
Например, если указать такое регулярное выражение:
То получим список всех запросов, которые начинаются со слова "как" (а также со слов "какой", "какие", "какая"):

Такие запросы отлично подходят для информационных статей, даже если сайт коммерческий.
Если задействовать такое выражение:
бесплатно$
То получим все запросы, которые заканчиваются на слово "бесплатно":

Таким образом, можно сразу избавиться от любителей халявы 🙂 . Нет, как можно набирать запрос "кондиционер бесплатно"? Жажда халявы не имеет границ. Это как в том анекдоте "Приму Бентли в дар" 😉 . Ладно, надо серьезнее.
Если нам нужно найти все фразы, которые содержат буквы латинского алфавита, то пригодится такое выражение:
Приведу примеры других регулярных выражений, которые я использую:
^(\S+?\s\S+?)$ - все запросы, состоящие из 2 слов
^(\S+?\s\S+?\s\S+?)$ - состоящие из 3 слов
^(\S+?\s\S+?\s\S+?\s\S+?)$ - состоящие из 4 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 5 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 6 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 7 слов
^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ - из 8 слов
Поиск по запросам, состоящих из 6 и более слов полезен, так как часто они содержат много мусорных фраз.
В программе имеется и другая возможность найти такие запросы – просто выберите в выпадающем меню нужный пункт ниже:

2. Список стоп-слов
Для чистки поисковых запросов имеет смысл создать список нежелательных слов, которые вы хотите удалить в собранных запросах.
Например, если у вас коммерческий сайт, то можно использовать такие стоп-слова:
бесплат
качат
реферат
Я специально пишу некоторые слова только частично, чтобы охватить все возможные варианты. Например, использование стоп-слова "бесплат" позволит не собирать запросы, содержащие:
бесплатно
бесплатный
Стоп-слово "качат" даст возможность не собирать запросы, которые включают в себя:
скачать
качать
В программе Кей Коллектор во вкладке "Сбор данных" переходим в пункт "Стоп-слова":

И добавляем нежелательные слова через опции "Добавить списком" или "Загрузить из файла":



Перейдя в основное окно программы, мы увидим, сколько запросов отмечено по указанным стоп-словам:

Останется только найти отмеченные запросы, кликнуть по ним правой мышкой и выбрать "Удалить отмеченные строки":

Товарищи, которые хотят кондиционеры бесплатно, нас не интересуют 🙂 .
Можно даже не искать пример отмеченного запроса, а сразу кликнуть правой мышкой на любом запросе, даже который не отмечен, и выбрать "Удалить отмеченные строки".
Я также активно использую в качестве стоп-слов названия городов. Например, мне нужно собрать запросы только для Москвы. Поэтому использование стоп-слов с названиями городов позволит не собирать запросы, которые содержат в себе названия других городов.
Приведу примеры таких стоп-слов:
санкт
петер
питер
Все эти слова позволят не собирать запросы, содержащие различные варианты названия Санкт-Петербурга. Как и в предыдущем примере, я использую сокращенные варианты названий городов.
Также советую использовать в качестве стоп-слов цифры предыдущих годов, так как запросы с ними практически никто набирать не будет:
Поделюсь с вами своим списком стоп-слов, который содержит:
- города России
- города Украины
- города Белоруссии
- города Казахстана
А также мой список общих стоп-слов (бесплат, качат, реферат, pdf и т.д.).
Полный список стоп-слов может получить любой желающий абсолютно бесплатно.
Этот метод я использую очень активно. В любой тематике будут запросы, которые не получится удалить с помощью тех же стоп-слов или групп слов.
Например, стоп-слова не учитывают всего разнообразия словоформ, которые могут быть.
Допустим, ваша компания занимается продажей кондиционеров. При этом такие услуги, как заправка и ремонт не предоставляет.
Можно при просмотре запросов отправлять неподходящие слова в список стоп-слов с помощью указанной иконки:
![]()

Но при этом не будут охвачены запросы, которые содержат слова "заправить", "заправки" и т.д.
Для того, чтобы задействовать весь спектр подобных запросов, которые вы хотите удалить, и избавить себя от ненужной работы, делаем следующее.
При просмотре списка запросов часть слов не будет охвачена, как в примере выше.
Я открываю текстовый файл и вписываю в него только часть от слова "заправка", чтобы охватить все возможные словоформы на его основе:

В результате получу список поисковых запросов со всеми возможными вариантами слова "заправка":

Для сброса быстрого фильтра нажмите на указанную галочку:
Данный метод позволяет прямо в процессе работы удалять все словоформы тех запросов, которые вам не подходят. Главное – использовать сокращенные варианты слов для максимального охвата.
Во многих тематиках некоторые методы сбора ключевых слов с таких источников, как, например, поисковые подсказки, в итоге дают много мусорных запросов. Подсказки тоже нужно использовать, в них попадаются отличные ключевые слова, но и чистить их тоже необходимо.
Для быстрой очистки таких запросов имеет смысл воспользоваться данным способом.
Кликаем по указанной иконке в верхней части колонки "Источник":

После этого выбираете нужный источник. Я обычно работаю с подсказками разных поисковых систем:

Можно работать с подсказками каждого поисковика по отдельности, а можно добавить условие:

Применить "ИЛИ" вместо "И" и выбрать сразу несколько источников подсказок:

В итоге получите список запросов из поисковых подсказок сразу из нескольких источников – Яндекса, Гугла и т.д.
По своему опыту могу сказать, что чистить запросы по такому списку на основе источников намного быстрее и эффективнее.
Этот способ знают все. Он заключается в обычном выделении одного или нескольких запросов галочкой, клике правой мышкой и выборе пункта "Удалить отмеченные строки":

Этот метод я использую на заключительной стадии. После всех чисток нужно еще раз просмотреть все запросы и вручную удалить те, которые не подходят, но прошли все предыдущие фильтры.
Так сказать, это финальная "полировка" семантического ядра 🙂 .